- Таблицы кодировок ASCII CP1251 windows1251 ISO-8859-5 основные отличия и применение
- ASCII, CP1251, windows-1251, ISO-8859-5: основные отличия и применение
- Кодировка CP1251, windows-1251
- Таблица кодировки ISO-8859-5 (is0-8859-5)
- Unicode и utf-8
- Таблица IS0-8859-5
- Таблица ASCII
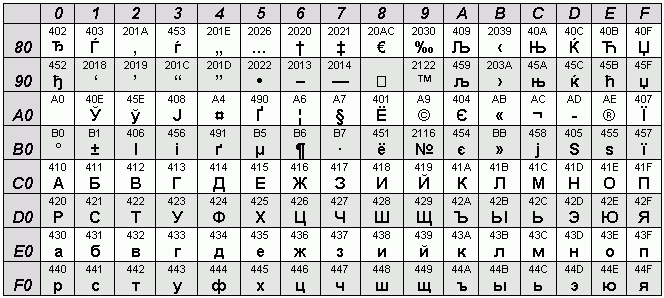
- Таблица CP1251, windows-1251
- Кодирование текстовой информации
- Кодировка UTF-8, Unicode Transformation Format
- Видео:
- Недостатки PHP-Fusion. Если сайт вопросительными знаками сделать кодировку cp1251
Таблицы кодировок ASCII CP1251 windows1251 ISO-8859-5 основные отличия и применение

Кодировка — это процедура преобразования символов текстовой информации в последовательность байтов, которая используется для передачи и хранения данных. В частности, кодирование широко используется при работе с кириллическими символами в текстовом формате. В данной статье мы рассмотрим основные таблицы кодов ASCII CP1251, windows-1251 и ISO-8859-5 и выясним их отличия и применение.
ASCII — это стандартная таблица кодов символов, зависящая от 7-битного кодирования. Она была разработана в рамках MS-DOS и состоит из 128 символов. Однако, задание большего количества символов в таблице требовало дополнительной информации для перевода кода в символ. Это привело к созданию таблиц кодировки, таких как CP1251 и windows-1251.
CP1251 и windows-1251 являются алфавитными кодировками, в которых каждый символ представлен одним байтом. Они используются для кодирования кириллических символов в тексте. Отличие между ними заключается в том, каким образом они кодируют символы, отличные от ASCII. CP1251 использует старший бит для знака, а windows-1251 освобождает этот бит, чтобы заменить ASCII-символы на русские.
ISO-8859-5 — это таблица кодировки, используемая в компьютерном представлении кириллицы. Она является частью кодировок ISO 8859, разработанных Международной организацией по стандартизации. В отличие от ASCII и CP1251, ISO-8859-5 включает в себя полный набор кириллических символов и не требует дополнительной информации для перевода кода в символ. Она также можно использовать для работы с другими языками, использующими кириллицу.
При создании текстового документа в формате ASCII, CP1251 или windows-1251, набор символов ограничен кодировкой. Если вы попытаетесь внести символ, отсутствующий в таблице кодировки, он будет закодирован и отображаться специальным символом. Однако, при использовании кодировки UTF-8, которая является стандартом Unicode, можно использовать практически любой символ, включая кириллические.
Таким образом, таблицы кодировок ASCII CP1251, windows-1251 и ISO-8859-5 являются основными инструментами для кодирования кириллических символов в текстовом формате. Они обладают своими отличиями и применяются в различных ситуациях. Если вам необходимо работать с ограниченным набором символов, например, при создании простых текстовых документов, вы можете использовать одну из таблиц кодировки. Если же вам необходимо работать с большим количеством символов, включая кириллические, рекомендуется использовать кодировку UTF-8.
ASCII, CP1251, windows-1251, ISO-8859-5: основные отличия и применение
Кодировка CP1251, windows-1251
Однако таблица ASCII содержит только ограниченное количество символов, а именно символы английского алфавита, цифры и некоторые специальные символы. Для представления кириллических символов была разработана дополнительная таблица кодировки — CP1251 (также известная как windows-1251), которая добавляет к таблице ASCII кириллические символы. Поэтому CP1251 позволяет закодировать значительно большее количество символов по сравнению с ASCII.
Таблица кодировки ISO-8859-5 (is0-8859-5)
ISO-8859-5 (также известная как is0-8859-5) — это еще одна таблица кодировки, которая используется для представления кириллических символов. Эта таблица содержит символы кириллицы, а также некоторые символы, используемые в других языках, например, болгарский или македонский. ISO-8859-5 также использует один байт для представления каждого символа.
При использовании кодировки CP1251 или windows-1251 символы кириллицы представлены двумя байтами, что позволяет представить большее количество символов, чем ASCII. Также стоит отметить, что таблица CP1251 используется в операционной системе MS-DOS для представления кириллических символов.
Unicode и utf-8
Для решения проблемы с ограниченным количеством символов в кодировках ASCII, CP1251 и ISO-8859-5 был разработан стандарт Unicode. Unicode предоставляет универсальный набор символов, который включает в себя символы различных языков и позволяет представление их с помощью разных кодов.
В свою очередь, utf-8 (Unicode Transformation Format-8) является одной из самых распространенных схем кодирования Unicode, которая позволяет представлять символы в переменной длине. В utf-8 каждому символу может быть назначено различное количество байтов в зависимости от его кода. Это делает utf-8 эффективным и универсальным методом кодирования текстовой информации, который поддерживается большинством современных систем и программ.
Применение кодировок
Кодировки ASCII, CP1251, windows-1251 и ISO-8859-5 имеют различные области применения в зависимости от конкретной задачи или требований. Например, если работа ведется с текстовыми документами, содержащими только символы английского алфавита, кодировка ASCII будет достаточной. Однако, если необходимо работать с кириллическими символами, тогда целесообразнее использовать CP1251, windows-1251 или ISO-8859-5.
Если требуется универсальная поддержка большого количества символов разных языков, рекомендуется использовать представление текста в кодировке utf-8. В зависимости от требований и области применения, следует выбрать наиболее подходящую кодировку для конкретной процедуры кодирования или декодирования текстовой информации.
Таблица IS0-8859-5
В таблице IS0-8859-5 каждый символ представлен одним байтом, в отличие от кодировки UTF-8, где символы могут быть представлены разным количеством байтов. Таблица следует алфавитному порядку, и ее можно просмотреть и редактировать в текстовом редакторе или блокноте.
Для применения таблицы IS0-8859-5 необходимо выполнить процедуру кодирования текста, используя эту таблицу. В текстовом документе, где требуется кодирование в IS0-8859-5, необходимо выбрать эту кодировку в параметрах документа.
IS0-8859-5 часто используется в ситуациях, когда необходимо перевести текст на кириллице из кодировки windows-1251 в кодировку, совместимую с Unicode. После этого текст можно будет отображать и обрабатывать в программном обеспечении, поддерживающем Unicode.
Таблица IS0-8859-5 содержит множество символов, которые не были представлены в таблице windows-1251, и предоставляет дополнительные возможности для работы с кириллическими текстами.
Таблица ASCII
Каждый символ в таблице ASCII представлен числом (кодом), который состоит из одного байта. Символы в таблице расположены по порядку в алфавитном виде, начиная с буквы «A» и заканчивая специальными символами.
Однако таблица ASCII не содержит символы кириллицы, используемой в русском языке. Для кодирования кириллических символов в текстовом документе на русском языке в MS-DOS и Windows было разработано несколько других таблиц кодировки, таких как CP1251 (Windows-1251) и ISO-8859-5.
Таблица кодировки CP1251, также известная как Windows-1251, была разработана компанией Microsoft и используется для кодирования символов, используемых в кириллице. Дополнительная таблица содержит кириллические символы, такие как буквы алфавита и специальные символы.
В кодировке CP1251 каждый символ кириллицы представлен одним байтом, и эта таблица совместима с таблицей ASCII. Это позволяет использовать как латинские, так и кириллические символы в одном текстовом документе.
Кроме того, существуют и другие таблицы кодировки для представления кириллических символов, такие как ISO-8859-5 и UTF-8. Таблица кодировки ISO-8859-5 содержит кириллические символы, представленные одним байтом. UTF-8 — это многосимвольная таблица кодировки Unicode, которая использует переменное количество байтов для представления символов разных языков, включая кириллицу.
При работе с текстовыми документами на русском языке необходимо задать правильную таблицу кодирования для корректного отображения символов. Если таблица кодировки не указана, текстовый редактор или программное обеспечение может использовать таблицу по умолчанию, которая может отличаться в разных системах.
Использование соответствующей таблицы кодирования становится особенно важным при обмене информацией между различными системами и программами, где может возникнуть проблема с отображением кириллических символов.
Таблица CP1251, windows-1251
Таблица кодировок CP1251 и windows-1251 содержат символы, которые отсутствуют в ASCII, включая все буквы кириллического алфавита, а также дополнительные символы и знаки препинания. Таким образом, эти кодировки предоставляют возможность записи и передачи информации на русском и других славянских языках.
CP1251 и windows-1251 распространены в операционных системах MS-DOS и Windows, которые широко использовались в прошлом. Для задания кодировки текстового документа в этих системах используется кодировка CP1251 или windows-1251.
При использовании CP1251 или windows-1251 каждый символ кириллицы представлен одним байтом. Это позволяет экономить пространство и упрощает процедуру кодирования и декодирования. Однако, с появлением Unicode и дополнительной информации на других языках, которые требуют большего количества символов, эти кодировки становятся ограниченными.
Для более широкой поддержки различных языков и символов созданы другие кодировки, такие как UTF-8 и ISO-8859-5 (или is0-8859-5). UTF-8 является универсальной кодировкой, способной представить символы всех языков, включая кириллицу. ISO-8859-5, с другой стороны, является расширением ASCII, подобно CP1251 и windows-1251, но предоставляет только символы кириллицы.
Для преобразования текста из кодировки CP1251 или windows-1251 в другие кодировки или наоборот, можно использовать таблицу соответствия символов. Такая таблица определяет порядок кодов символов в текстовом файле и позволяет программам и системам правильно интерпретировать закодированный текст.
Одним из способов просмотра и редактирования текстовых файлов в кодировке CP1251 или windows-1251 является использование текстового редактора, такого как блокнот в Windows. При открытии файла в блокноте, программа автоматически определяет кодировку и отображает текст в соответствии с ней. Если текст отображается некорректно, можно попробовать изменить кодировку на UTF-8 или другую подходящую.
Кодирование текстовой информации
Процедура кодирования заключается в том, что каждый символ из текстовой информации преобразуется в последовательность байт, которая затем будет использоваться для передачи, хранения или отображения символов. В кодировке cp1251 каждый символ кириллического алфавита занимает один байт, и таблица символов содержит 256 значений. В кодировке ISO-8859-5 количество символов сокращено до 256, и для кодирования кириллических символов используется дополнительная таблица символов.
Для выполнения кодирования в кодировке cp1251 может быть использован такой инструмент, как блокнот в операционной системе Windows. В нем символы закодированы в порядке, заданном таблицей кодировки, и сохраняются в текстовом формате. При открытии документа в другой системе с кодировкой ISO-8859-5 коды символов будут прочитаны неправильно, поскольку расположение символов будет отличаться.
Однако, с развитием использования Unicode, который представляет собой универсальную таблицу символов, стандартное кодирование текстовой информации испытывает некоторые проблемы. Для кодирования символов Unicode используется формат UTF-8, который может использовать разное количество байт для кодирования символов в зависимости от их кода. Это позволяет учесть большое количество символов разных языков и наборов символов.
В итоге, кодирование текстовой информации является важной частью работы с различными системами и программами. Правильное выбор кодировки и использование соответствующих инструментов, таких как таблицы кодировок, позволяет корректно отображать и обрабатывать информацию на разных устройствах и платформах.
| Таблица кодировки cp1251 (windows-1251) | Таблица кодировки ISO-8859-5 |
|---|---|
| Символы кириллицы | Символы кириллицы |
| Символы латиницы | Дополнительные символы |
Кодировка UTF-8, Unicode Transformation Format
UTF-8 является частью стандарта Unicode, который определяет универсальный набор символов для всех языков и письменностей. В отличие от других кодировок, где каждый символ соответствует определенному числу байтов, UTF-8 использует переменную длину кодовых единиц. Например, символы из ASCII таблицы кодируются одним байтом, а дополнительные символы, такие как кириллические, занимают от двух до четырех байтов.
Кодировка UTF-8 используется для хранения и обмена информацией на компьютерах, а также веб-страницах и документах. Она поддерживается практически всеми современными операционными системами, программным обеспечением и браузерами. Для просмотра или редактирования текстов, закодированных в UTF-8, можно использовать любой текстовый редактор, такой как Блокнот, или специальные программы для работы с текстовыми файлами.
Для использования кодировки UTF-8 в документе HTML, необходимо указать соответствующую метаинформацию в заголовке документа:
<meta charset="utf-8">
В этом случае браузер будет знать о том, что документ содержит информацию, закодированную в UTF-8, и сможет правильно отображать все символы кириллицы и других алфавитов.
Таким образом, кодировка UTF-8 представляет собой дополнительную таблицу кодирования, в которой символы из различных алфавитов и письменностей могут быть закодированы в переменное количество байтов. Это позволяет использовать большое количество символов и гарантирует правильное отображение текста на устройствах и программном обеспечении, поддерживающих эту кодировку.
Видео:
Недостатки PHP-Fusion. Если сайт вопросительными знаками сделать кодировку cp1251
Недостатки PHP-Fusion. Если сайт вопросительными знаками сделать кодировку cp1251 di Vladimir Kazakov: PHP-Fusion 189 visualizzazioni 7 anni fa 8 minuti e 43 secondi